
آزمایشگاه Thinking Machines اعلام کرده که API تکرین Tinker اکنون بهصورت عمومی در دسترس است و سه قابلیت جدید از جمله مدل Kimi K2، نمونهگیری همخوان با OpenAI و ورودی تصویری از طریق مدلهای زبان تصویری Qwen3-VL به آن اضافه شده است. این API به مهندسین هوش مصنوعی این امکان را میدهد که مدلهای پیشرفته را بدون نیاز به زیرساختهای پیچیده آموزش دهند.
قابلیتهای Tinker
Tinker یک API آموزشی است که بر تطبیق مدلهای زبان بزرگ تمرکز دارد. شما میتوانید با یک حلقه ساده پایتون که بر روی دستگاههای تنها با CPU اجرا میشود، داده یا محیط RL، اتلاف و منطق آموزشی را تعریف کنید. سرویس Tinker آن حلقه را به یک خوشه GPU منتقل کرده و محاسبات مورد نظر شما را اجرا میکند.
API قابلیتهای پایهای مانند forward_backward برای محاسبه گرادیانها و optim_step برای بهروزرسانی وزنها فراهم میکند. بههمین دلیل، برای افرادی که میخواهند یادگیری نظارتشده یا بهینهسازی ترجیحات را بدون مدیریت پیچیدگیهای GPU اجرا کنند، مفید است.
قابلیتهای Kimi K2 و شرایط عمومی
در این بهروزرسانی، Tinker به هیچ لیست انتظاری نیاز ندارد و کاربران میتوانند مدلهای موجود و قیمتها را مشاهده و بهصورت مستقیم آنها را اجرا کنند. اکنون کاربران میتوانند مدل دلیلگیری moonshotai/Kimi-K2-Thinking را تطبیق دهند که با داشتن یک تریلیون پارامتر، برای ایجاد زنجیرههای طولانی فکر طراحی شده است.
نمونهگیری همخوان با OpenAI
Tinker یک رابط نمونهگیری بومی دارد که الگوی استنتاج معمول را بهکار میگیرد و با OpenAI همخوان است و امکان استفاده از URI مدل را فراهم میکند.
ورودی تصویری با Qwen3-VL در Tinker
قابلیت ورودی تصویری، دو مدل زبانی تصویری Qwen3-VL را معرفی میکند. این مدلها به توسعهدهندگان امکان ایجاد تونلهای آموزشی چندرسانهای را میدهند.
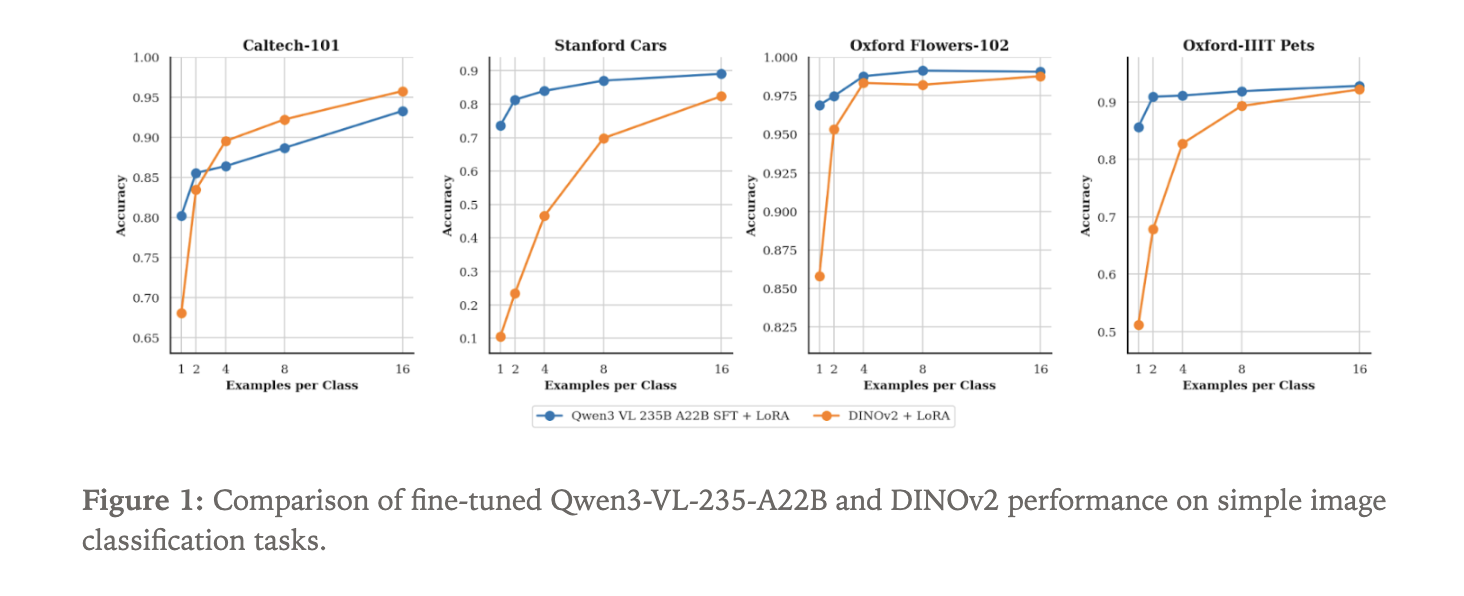
مقایسه Qwen3-VL با DINOv2 در طبقهبندی تصاویر
تیم Tinker مدل Qwen3-VL-235B-A22B-Instruct را بهعنوان یک دستهبند تصویر تطبیق داد و از چهار مجموعهداده استاندارد استفاده کرد. مدل Qwen3-VL یک مدل زبان با ورودی تصویری است که نام کلاس را به صورت متنی تولید میکند.
نکات کلیدی
- Tinker آزادانه در دسترس است و کاربران میتوانند مدلهای زبان با وزن باز را تطبیق دهند.
- پلتفرم از مدل Kimi K2 با پارامترهای ۱ تریلیونی پشتیبانی میکند.
- رابط همخوان با OpenAI امکان نمونهگیری سادهتر را فراهم میکند.
- ورودیهای تصویری از طریق مدلهای Qwen3-VL امکانپذیر شده است.
- مدل Qwen3-VL عملکرد بهتری نسبت به DINOv2 در طبقهبندی تصویر نشان داده است.