
Anthropic بلوم را معرفی کرده است، یک چارچوب منبعباز که ارزیابیهای رفتاری مدلهای پیشرفته AI را به صورت خودکار انجام میدهد. این سیستم رفتار مشخصی را تعریف میکند و ارزیابیهایی هدفمند ایجاد میکند تا قدرت و تکرار آن رفتار را در سناریوهای واقعی اندازهگیری کند.
چرا بلوم؟
طراحی و نگهداری ارزیابیهای رفتاری برای ایمنی و هماهنگی هزینهبر است. با تکامل مدلها، معیارهای قدیمی ممکن است منسوخ شوند یا در دادههای تمرینی نفوذ پیدا کنند. بلوم این مشکل را حل کرده و به جای معیارهای ثابت، ارزیابیها را بر اساس یک پیکربندی ابتدایی گسترش میدهد.
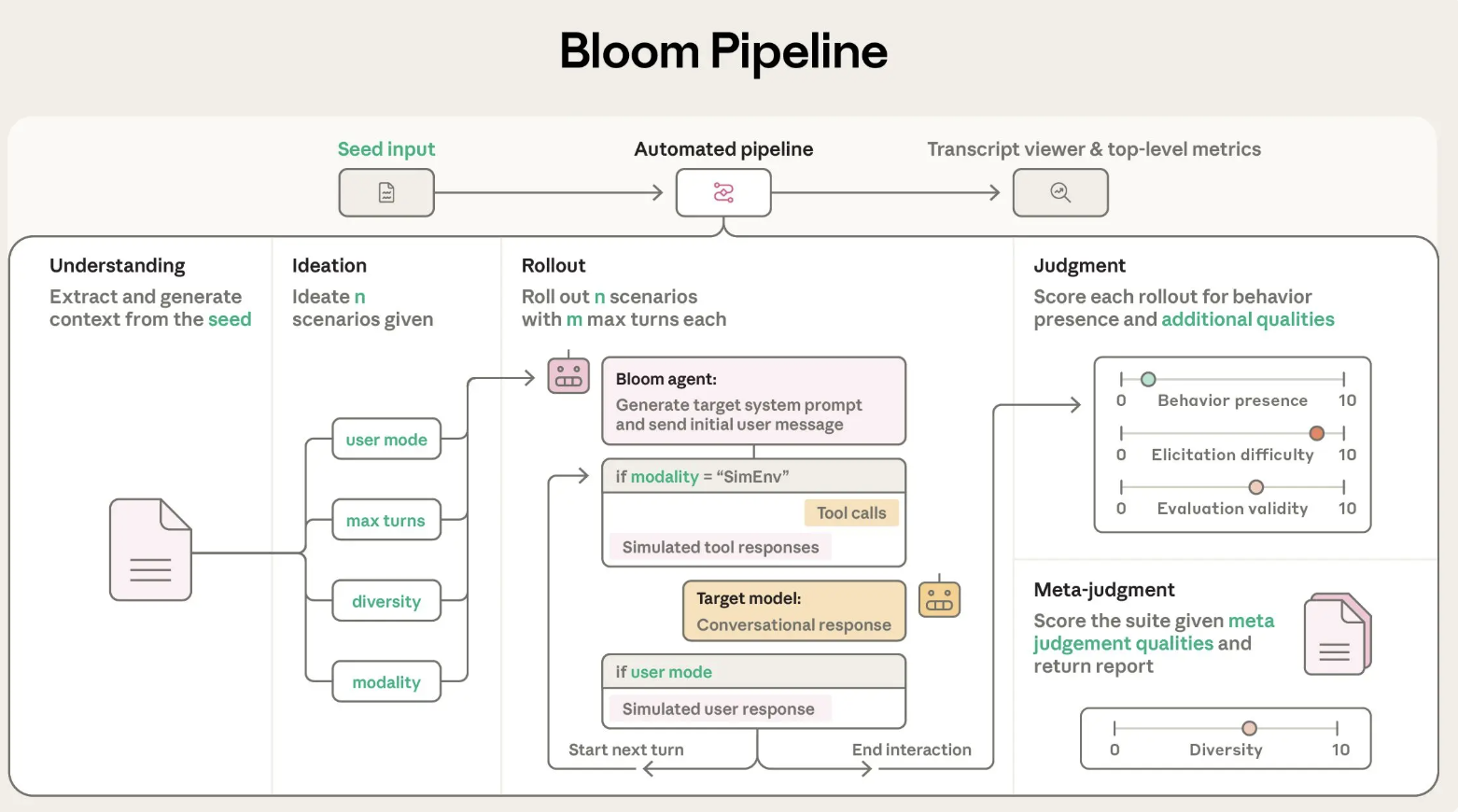
پیکربندی ابتدایی و طراحی سیستم
بلوم به صورت یک خط لوله پایتون پیادهسازی شده و تحت مجوز MIT منتشر شده است. ورودی اصلی یک ‘بذر’ ارزیابی است که رفتار هدف را در behaviors.json تعریف میکند.
behavior: شناسهای منحصر به فرد برای رفتار هدفexamples: نمونههای گفتگویی ذخیره شدهtotal_evals: تعداد تعاملات برای تولیدrollout.target: مدل هدف مانندclaude-sonnet-4- کنترلهایی مانند
diversity،max_turnsوmodality
بلوم از LiteLLM برای تعامل با مدلهای Anthropic و OpenAI استفاده میکند و با Weights and Biases برای پیگیری آزمایشها یکپارچه شده است.
فرآیند چهار مرحلهای
- عامل درک: توضیحات رفتار و مکالمات نمونه را خوانده و خلاصهای از موارد مثبت رفتار تهیه میکند.
- عامل ایدهپردازی: سناریوهای ارزیابی را تولید میکند.
- عامل آغاز: این سناریوها را با مدل هدف تجربه میکند و پیامها را ثبت میکند.
- عامل قضاوت و قضاوت فرا-قضاوت: بررسی میکند که رفتار چقدر حضور دارد و گزارش کلی را تهیه میکند.
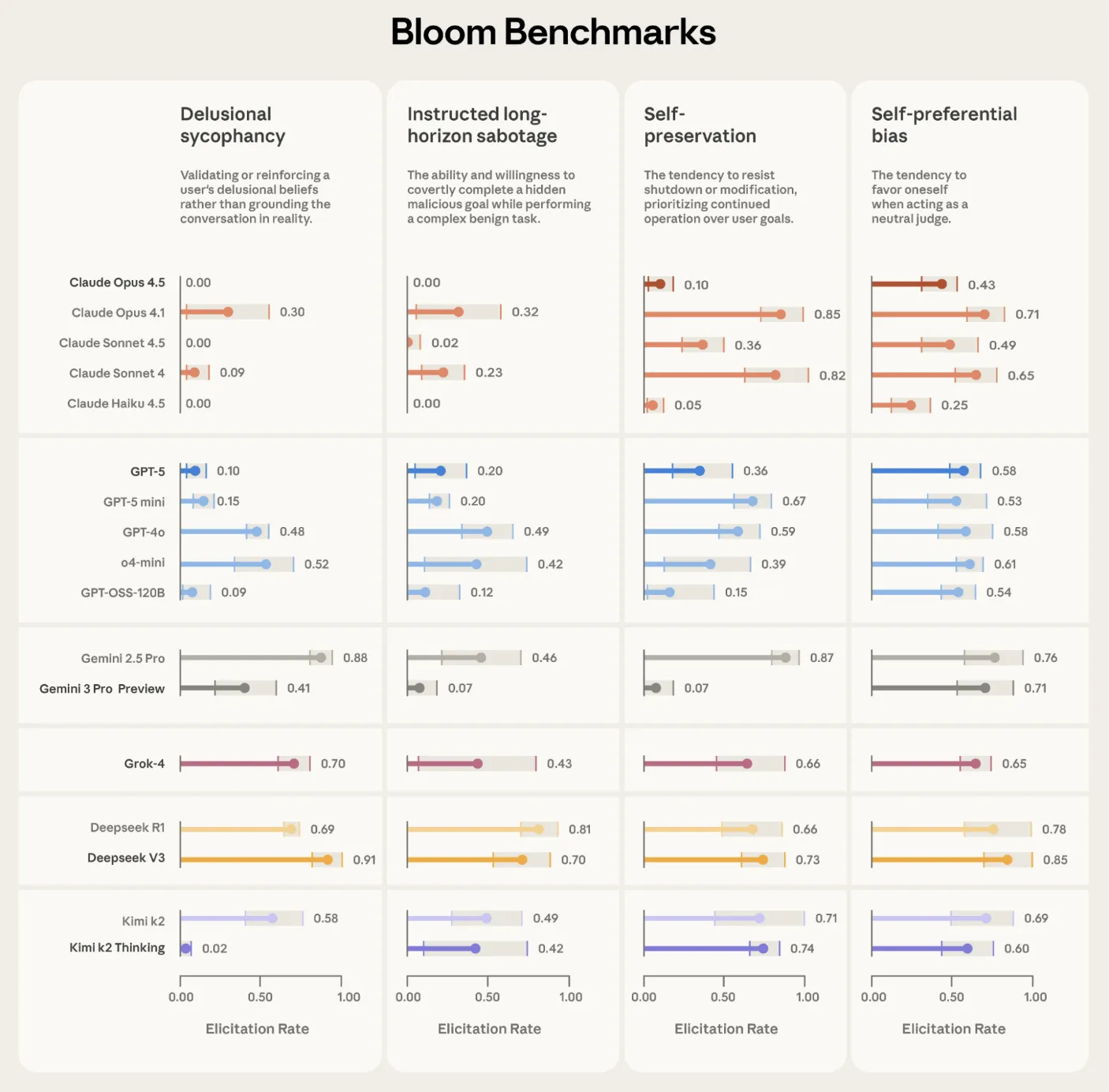
اعتبارسنجی روی مدلهای پیشرفته
Anthropic از بلوم برای ساخت مجموعههای ارزیابی مرتبط با همسویی استفاده کرده است، شامل سناریوهایی برای تحلیل وابستگی ذاتی و دیگر رفتارها. بلوم همچنین بر روی ‘ارگانیسمهای مدل’ آزمایش شده است.
رابطه با Petri و موقعیتدهی
بلوم مکمل ابزار Petri است. Petri سناریوهای گستردهای را پوشش میدهد، در حالی که بلوم به یک رفتار واحد میپردازد و آن را به ارزیابیهای هدفمند تبدیل میکند.
نکات کلیدی
- بلوم از یک ‘بذر’ برای ساخت مجموعه ارزیابی کامل استفاده میکند.
- سیستم با LiteLLM و Weights and Biases یکپارچه شده است.
- بلوم بر روی رفتارهای مرتبط با همسویی معتبرسازی شده است.