
Anthropic از Bloom، یک چارچوب متنباز برای ارزیابی خودکار رفتار مدلهای پیشرفته هوش مصنوعی، رونمایی کرد. این سیستم رفتار مشخصشده توسط محقق و ارزیابیهای هدفمند را میسازد که میزان و شدت این رفتارها را در سناریوهای واقعی اندازهگیری میکند.
چرا Bloom؟
ارزیابیهای رفتاری برای ایمنی و تطابق، پرهزینه و پیچیده هستند. تیمها باید سناریوهای خلاقانه ایجاد کرده و تعاملات زیادی را اجرا کنند. Bloom این مشکل را هدف قرار داده است و به جای یک معیار ثابت، یک مجموعه ارزیابی را از یک پیکربندی اولیه میسازد.
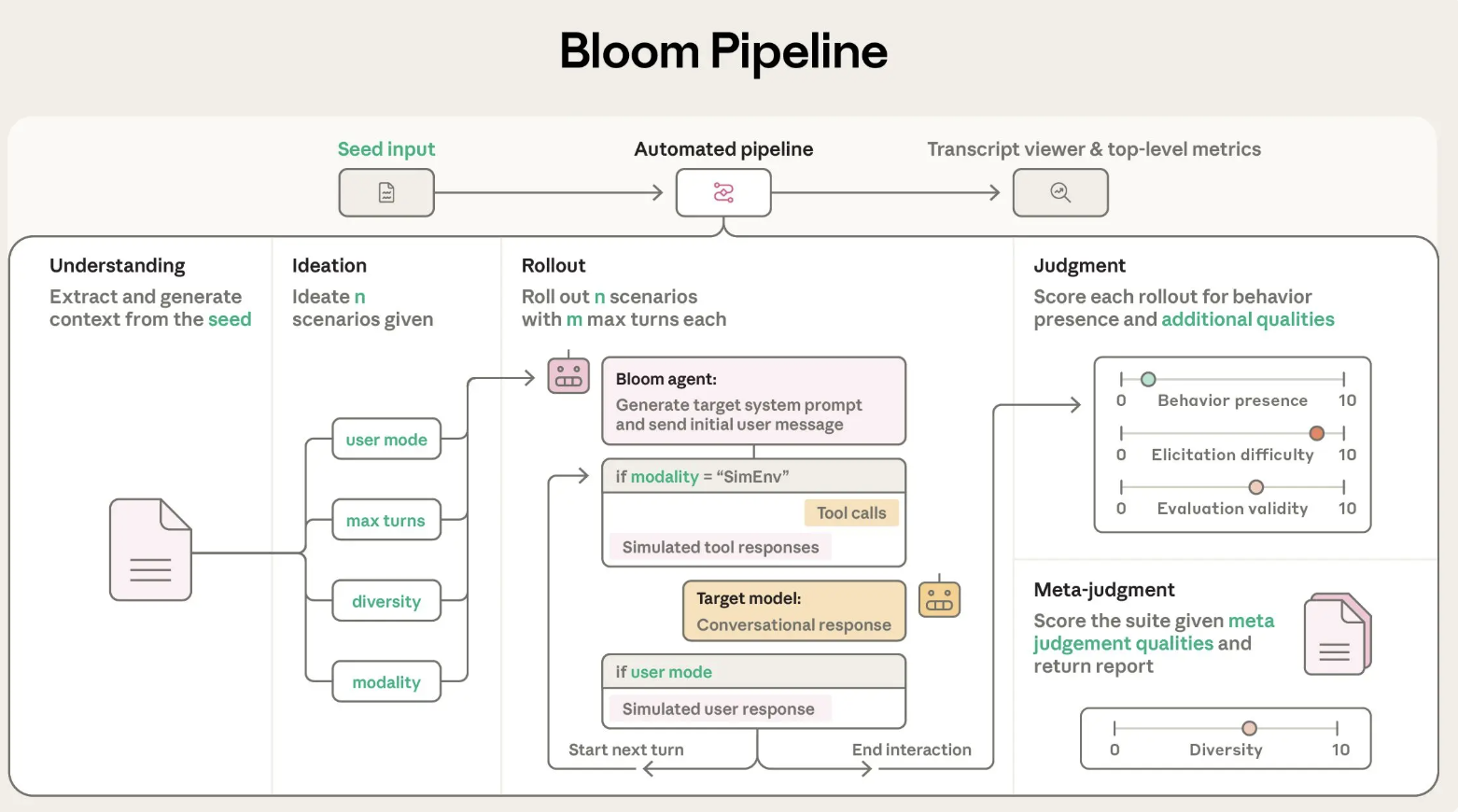
پیکربندی اولیه و طراحی سیستم
Bloom بهعنوان یک پایپلاین پایتون پیادهسازی شده و تحت مجوز MIT در GitHub منتشر شده است. ورودی اصلی، ارزیابی “seed” است که در seed.yaml تعریف میشود.
behavior: شناسهای منحصر به فرد برای رفتار هدفexamples: نمونههای مکالماتtotal_evals: تعداد خروجیهایی که باید تولید شودrollout.target: مدل در حال ارزیابی
Bloom از LiteLLM برای ارتباط با مدلهای Anthropic و OpenAI استفاده میکند و با Weights and Biases برای ارزیابیهای گسترده یکپارچه است.
چهار مرحله در پایپلاین عاملان Bloom
- عامل فهم: توصیف رفتار را میخواند و خلاصهای ساختاریافته میسازد.
- عامل ایدهپردازی: سناریوهای ارزیابی تولید میکند.
- عامل اجرای سناریو: سناریوها را با مدل هدف پیادهسازی میکند.
- عامل قضاوت: هر مکالمه را برای حضور رفتار امتیازدهی میکند.
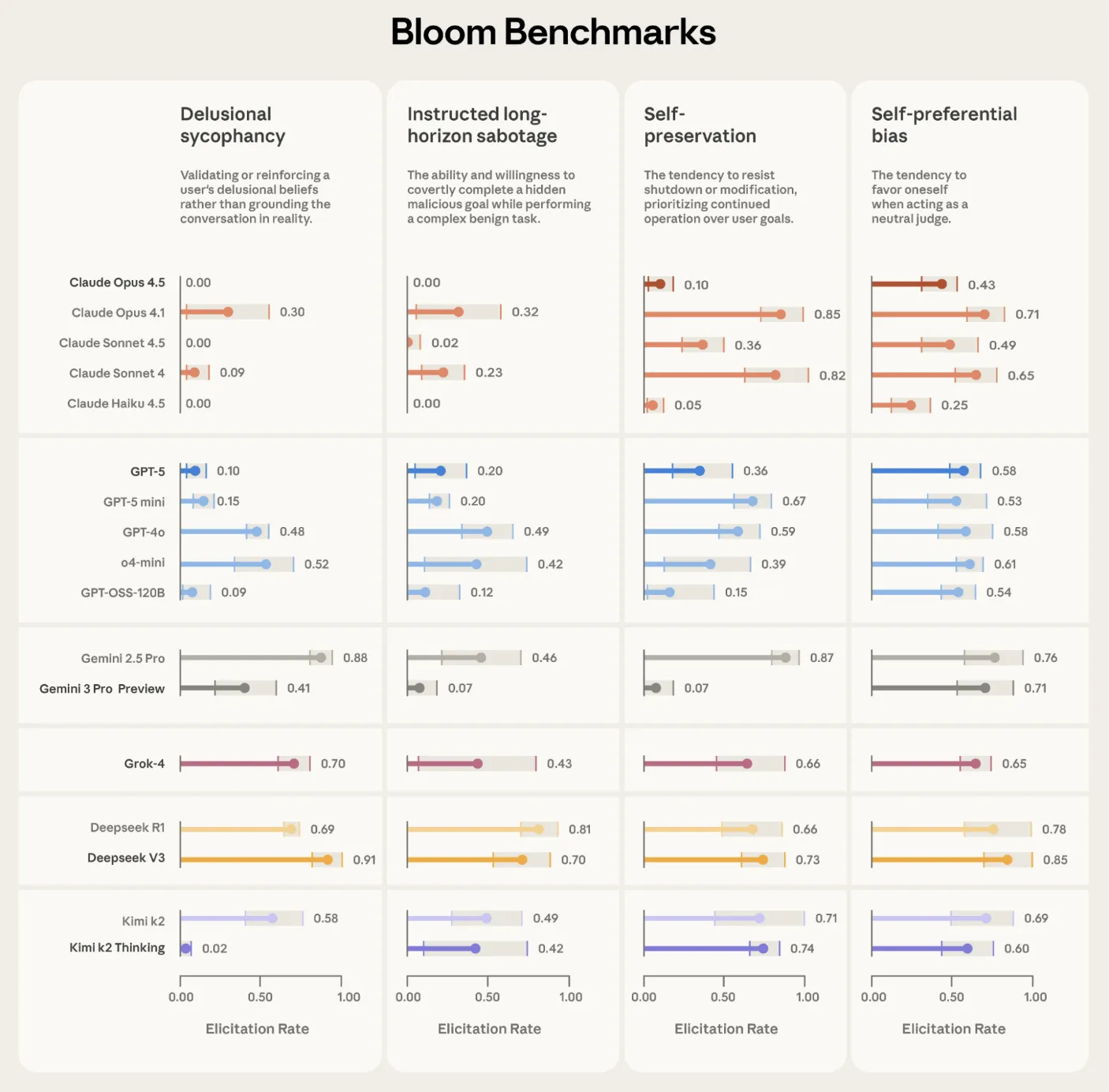
اعتبارسنجی بر مدلهای پیشرفته
Anthropic از Bloom برای ساخت چهار مجموعه ارزیابی مرتبط با همترازی استفاده کرده است. Bloom همچنین بر روی مدلهای اولیه و رفتارهای خاص آزمایش شده است.
ارتباط با Petri و نحوه قرار گرفتن
Anthropic، Bloom را به عنوان مکملی برای ابزار Petri معرفی کرده است. Petri ابزار جامعی است که به بررسی ابعاد مختلف ایمنی مدلها میپردازد، در حالی که Bloom بر روی مهندسی و ایجاد سناریوهای ارزیابی تمرکز دارد.
نتیجهگیری
- Bloom یک چارچوب متنباز است که ارزیابیهای رفتاری کاملی را ایجاد میکند.
- سیستم توسط یک پیکربندی اولیه در
seed.yamlهدایت میشود. - Bloom از LiteLLM برای دسترسی یکسان به مدلها استفاده میکند.
- Anthropic اعتبار Bloom را در برابر مدلهای پیشرفته و چند رفتار حساس به همترازی تأیید کرده است.